
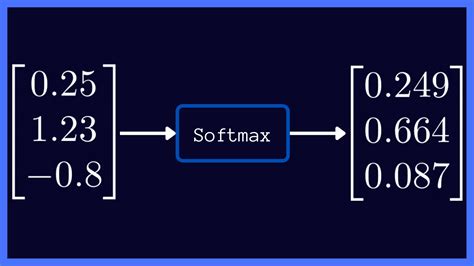
Also know, what does the Softmax function do?
Softmax function. Softmax is often used in neural networks, to map the non-normalized output of a network to a probability distribution over predicted output classes.
Subsequently, question is, when should I use Softmax activation? The softmax activation function is used in neural networks when we want to build a multi-class classifier which solves the problem of assigning an instance to one class when the number of possible classes is larger than two.
Similarly, you may ask, what is the derivative of Softmax?
The softmax layer and its derivativeThe weight matrix W is used to transform x into a vector with T elements (called "logits" in ML folklore), and the softmax function is used to "collapse" the logits into a vector of probabilities denoting the probability of x belonging to each one of the T output classes.
Why is it called Softmax?
It is unfortunate that Softmax Activation function is called Softmax because it is misleading. To understand the origin of the name Softmax we need to understand another function which is also sometimes called Softmax and rightly so . It is approximating the max function.



